[모니터링] 모니터링 플랫폼 알아보기
서비스를 안정적으로 운영하기 위해서는 전사 시스템에 대한 모니터링이 필수이며 SI 프로젝트에서 사내 인프라 모니터링을 담당하였었다.
서비스를 구축한 것은 아니었고 솔루션을 도입하여 운영만 하였었지만, 덕분에 장애 발생 시 Trace 하는 나만의 방식이 생겼었다. 하지만 결국 인프라 레벨에서만 확인할 수 있었고 애플리케이션 레벨에서의 문제는 파악하기 어려웠고 한계점으로 남았었다.
약 6개월간 운영하면서 느꼈던 장단점은 다음과 같았다.
장점
- 서비스(프로세스) DOWN 시 즉시 알람을 받아 다운타임을 줄일 수 있었다. (페일오버가 되면 더 좋겠지만 페일오버가 되더라도 알 수 있어야 했음)
- 서버 리소스 지표를 보고 메모리 누수 혹은 비정상적인 점유를 파악할 수 있었다.
- 테스트 시 지표 및 자료 분석이 가능했다.
- 장애 발생 전조 증상을 알람받을 수 있었으며 장애 조치 후 원인 파악 자료로 용이했다.
- 장애 발생 시 (인프라 - 네트워크 - 애플리케이션 - DB) 장애 원인을 배제해 나가기에 용이했다.
- 커스텀 로그 및 추가 요구 사항 반영이 유연했다.
- 서비스 디스커버리 기능은 없어 담당자 요청에 의해 로그 모니터링이 추가되어야했던점은 아쉬움
단점
- 모니터링 특성 상 현재 시점의 리소스를 파악하기 어려워 결국 서버 내에서 Trace 하는 방법도 필요했다. (수집 주기 1분, 평균값 혹은 수집 시점 데이터)
- 특정 서버 대상으로 실시간 수집 기능도 있었으나 많은 대상을 볼 수 없었음 (연계 서비스가 많아도 실시간 확인이 어려움, 성능 문제로 인한 유연한 확장 기능이 없었음)
- 많이 사용되는 지표들을 다 수집해서 보여주는 것 같으나 지표들이 어떤 상관관계가 있고는 본인이 알아야함 (이 지표가 높으면 문제야? => 확답이 어려움, 본인 파트가 아니면 떠넘기기 좋은 구조..)
개선하고싶었던 점?
- 담당자가 아니더라도 문제점을 빠르게 유추할 수 있는 정보를 주었으면 좋겠음 (알람에 정의된다던지,..)
- 단순 지표가 아닌 유의미한 데이터로 전처리되어 나오면 좋겠음 (굳이 들어가서 스크립트를 돌리던, 명령어로 상태를 체크해야 하던 작업이 없었으면 좋겠음)
- 이미 처리되었던 혹은 히스토리가 있는 유사 알림에 대해 묶어서 보여주는 기능이 있으면 좋겠음(완전히 동일한 내용에 대해서만 필터링이 되다 보니 커스텀 로그에 대해서 이전에 발생했던 로그에 대해 공유가 잘 되지 않았음)
최종 목표는 모니터링 시스템을 믿을 수 있고, 신경쓰지 않아도 되는 알람을 최대한 제거하며 빠르게 문제파악 및 분석, 해결에 도움이 되는 지표를 전달받을 수 있는 플랫폼을 구축하고 싶었다.
위의 경험을 바탕으로 클라우드 플랫폼을 구축하여 서비스한다면 어떤 모니터링 플랫폼이 적합할지 고민하고 설계하는 과정을 거쳐보려고 한다.
그중 첫 번째 챕터가 카카오 / 우아한 형제들 / 토스의 모니터링 플랫폼 사례 공유를 보고 모니터링 플랫폼을 어떻게 구축하였는지, 어떤 고민들을 해왔는지 알아보고, 벤치마킹해보려고 한다.
클라우드 플랫폼을 서비스한다면 어떤 모니터링 플랫폼을 구축할 수 있을지 차차 고민해보고자 한다.
토스 - SLASH21 / 서버 인프라 모니터링
https://toss.im/slash-21/sessions/1-2
토스의 서버 인프라 모니터링
서버 인프라를 효과적으로 트러블 슈팅할 수 있도록 노력한 경험과 모니터링 인프라를 운영한 경험을 공유합니다.
toss.im
토스의 서버 인프라 모니터링에서는 갑자기 발생하는 이슈가 자주 있으며 해결하기 어려웠다고 한다.
해당 이슈를 해결하기 위해서는 서비스 이슈를 확인하기 위한 Application Layer Metric을 가장 먼저 확인하며,
전체적인 트랜잭션 및 로그를 확인하여 어느 애플리케이션에서 문제가 있었는지 원인을 규명
- 로직이 복잡하거나 트랜잭션이 길 경우 파악이 어려움 => 서비스 메쉬 추적이 필요 (Service Discovery)
이후 네트워크 및 어플리케이션이 떠있는 머신의 문제가 있었는지 확인하는 절차를 거침

- Application Layer Metric
- 스프링 프레임워크 관련 메트릭 (JVM, Tomcat, JPA,..)
- 필요에 따라 node, go, python 메트릭 지원
- 오류와 가장 상관관계가 높은 메트릭
- Network Layer Metric
- 서비스와 서비스 사이통신
- 모든 네트워크 퍼널의 가시성 확보용
- OS Layer Metric
- OS 리소스 관련 지표 (리소스 분배, 에러 확인)
- 오류와 가장 상관관계가 낮음
=> 결국 Network와 OS Layer 메트릭은 오류와 상관관계가 낮았으며 이를 높이기 위한 개선 방안을 적용했다고 함
서비스 메쉬로 인프라가 변화하면서 네트워크 제어권이 강화되어 네트워크 메트릭 정보가 풍부해졌음
=> 인프라의 변화로 인해 네트워크 레이어의 오류 상관관계 확률이 높아졌으며, 이에 대한 메트릭을 수집하고 확인해야 할 케이스가 늘었음
발생 이슈는 다음과 같이 설명해 주었다.
[Network]
1. 서비스 디스커버리

클라이언트 사이드 LB를 이루다 보니 인스턴스 IP를 갖고 있어야 하는데, 해당 IP에 대한 요청에 대해
- Route 실패 - NR
- Health check 실패 - UH
- 요청이 실패 - UO
2. 요청 커넥션 이슈

커넥션 리셋에 의해 발생할 수 있는 이슈들..
- 클라이언트 간 커넥션 이슈가 발생했을 때 해당 Flag를 보고 원인 유추에 도움이 되었으며 특히 Istio 도입이 다양한 메트릭을 제공하여 편리했음
[OS]
CPU, MEM, DISK, 커널 변수 등 오류와 상관관계가 있는 리소스를 파악하기 어려우며 경험에 의한 인사이트에 의존하는 경우가 많았음.
1. Use Method 기법을 통한 하드웨어 요소 배제해 나가기
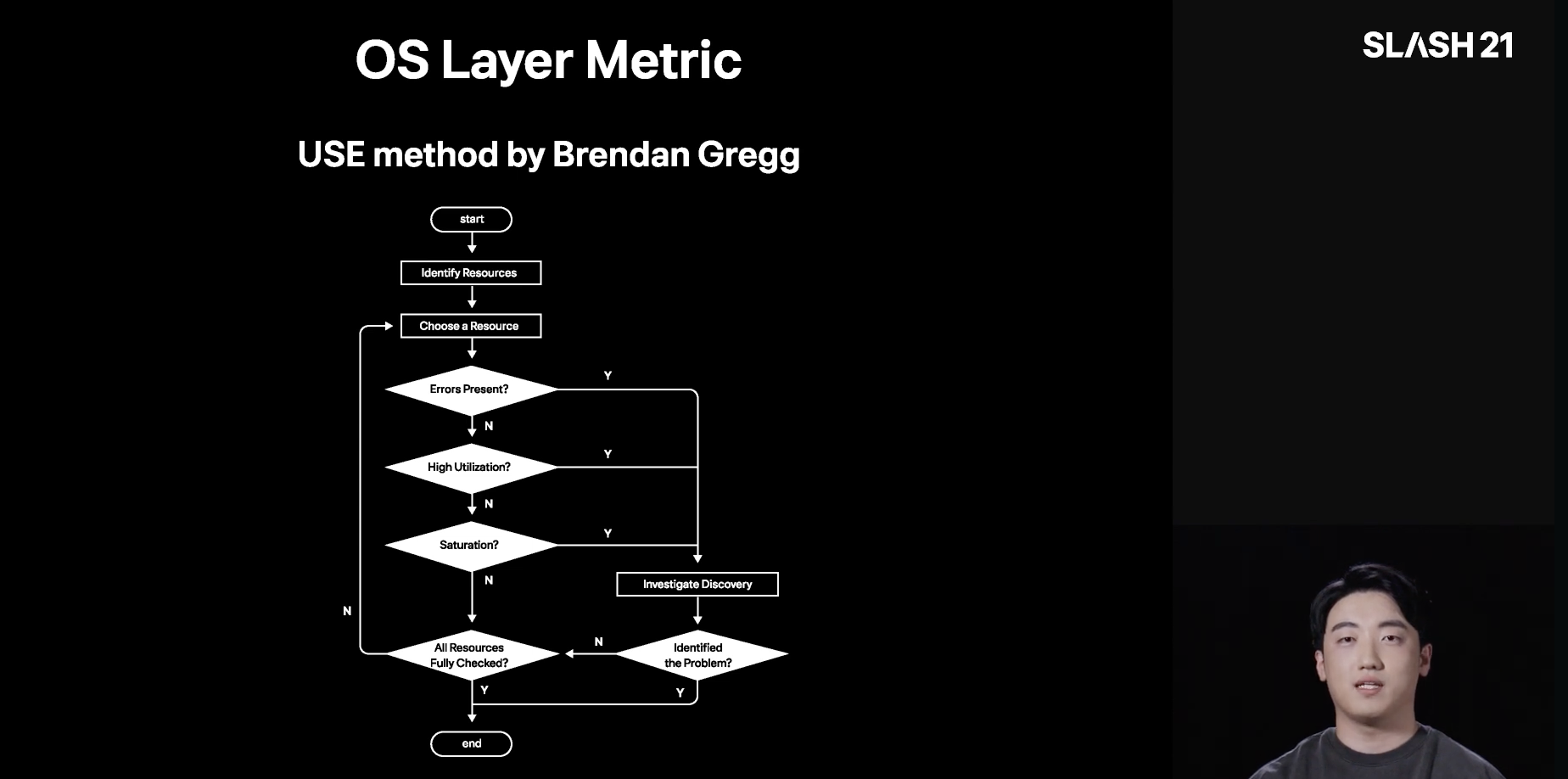
각 하드웨어에서 에러가 있는지, 사용률이 높은지, 포화 상태인지 확인하여 배제해 나가는 것으로 모니터링을 체계화하였음
2. OS 리소스별 상관관계를 높이고자 지표를 정의함
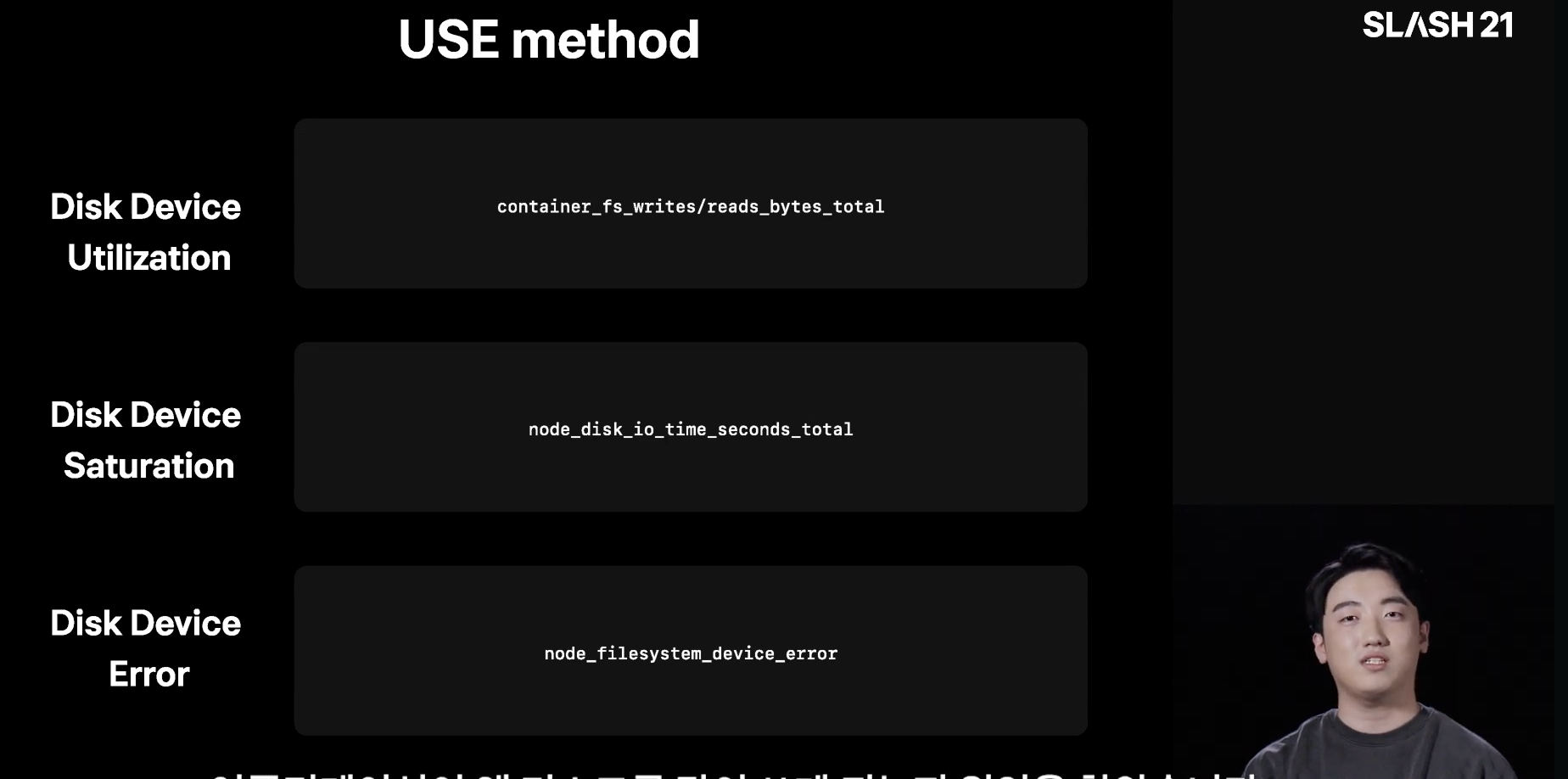
그래서 지금 CPU가 포화상태야? 언제부터? 에 대한 지표를 바로 확인할 수 있도록 Saturation 지표를 정의하는 등 오류와의 상관관계를 높이는 지표를 정의하였음
[정리]
토스의 서버 모니터링은 효과적인 트러블 슈팅이라는 목적을 가지고 모니터링 인프라를 개선해 나갔으며 해당 영상에서 전달해 준 기법 및 지표는 참고하여 적용하기 좋을 것으로 판단됨
모니터링 플랫폼을 어떤 방식으로 구축하고 설계했느냐보다 어떤 지표를 수집하여 문제를 해결해 나갈것이냐에 중점을 두었다고 느껴졌고, 서비스 오류 문제 해결을 위한 모니터링 생태계를 구축하자는 목표를 수립할 수 있었다.
카카오 - KEMI(Kakao Event Metering & monitoring)
https://tech.kakao.com/posts/333
카카오의 전사 리소스 모니터링 시스템 - KEMI(Kakao Event Metering & monItoring) - tech.kakao.com
KEMI(Kakao Event Metering & monItoring)는 카카오의...
tech.kakao.com
카카오에서는 100개가 넘는 클러스터를 모니터링하고 장애 시 알림을 받을 수 있도록 오픈소스와 자체 제작한 기능을 종합한 모니터링 및 알림 기능을 사용한다고 한다.
카카오의 기술 블로그에서는 아키텍처를 설명하며 어떤 구조로 로그와 메트릭을 수집하는지에 대해서 공유해 주었다.
KEMI(Kakao Event Metering & monItoring)는 카카오의 전사 리소스 모니터링 시스템입니다. 서버, 컨테이너와 같은 리소스의 메트릭 데이터를 수집해서 보여주고 설정한 임계치에 따라 알림을 보내주는 KEMI-STATS과 ETL을 통해 수집한 log를 대시보드 형태로 보여주거나 실시간 알림을 할 수 있는 KEMI-LOG로 구성되어 있습니다.
-출처: tech.kakao.com
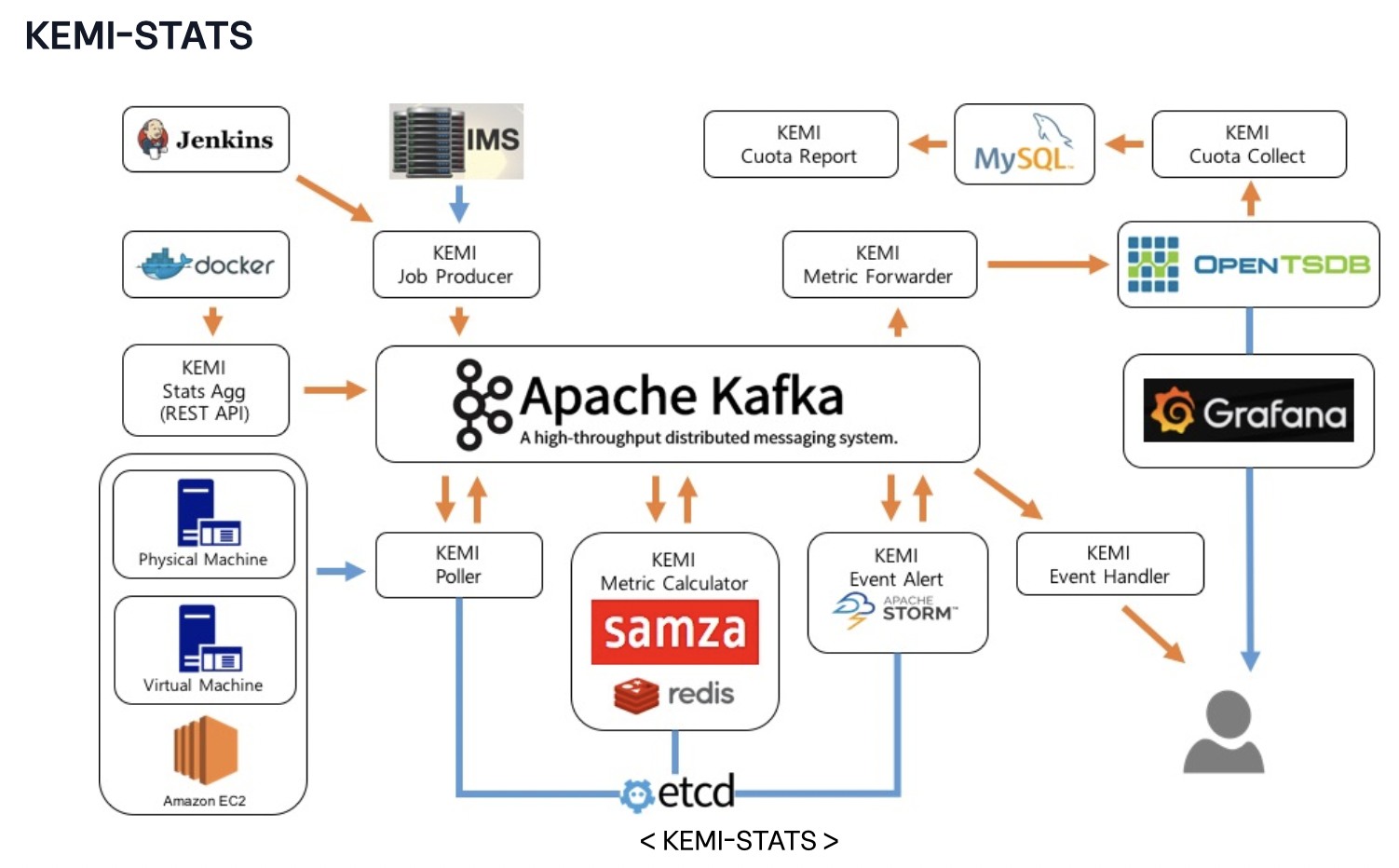
리소스 중 서버(physical machine, virtual machine, amazon ec2)의 경우 polling방식으로 SNMP를 이용하여 시스템 메트릭을 수집

- job이 시작되면 KEMI의 Job Producer가 IMS(Infrastructure Management System)라는 카카오 인프라 관리 시스템에서 데이터를 가져올 대상을 받아와서 kafka의 polling job queue topic에 넣어 놓습니다.(이렇게 매 주기마다 호스트 목록을 새로 가져오는 이유는 서버가 추가되거나 빠지는걸 바로 반영하기 위해서입니다.)
- 목록을 IMS에서 받아온다는 것은 서버의 목록을 관리하는 시스템이 하나 있다는 것이며 어떻게 관리되고 있는 시스템인지는 모르겠음, 꼭 필요한가? 는 모르겠음 (특정 파일로 관리되는 것인지 다른 곳에서 활용되는 것인지 파악이 필요해 보임)
- job으로 수집을 표현하며, job은 1분 주기이므로 1분마다 대상 서버를 kafka의 polling job queue topic에 넣어둠
- polling job queue topic을 보고 있던 KEMI의 Poller가 각 대상들에서 시스템 메트릭을 가져와서 다시 kafka에 저장합니다.(이때 그 호스트가 속한 서비스가 어떤 메트릭들을 수집할지를 etcd에 저장해 두고 사용합니다. 그래서 추가로 필요한 메트릭이 있을 때 Poller를 재시작하지 않고도 etcd에 있는 정보만 업데이트하면 수집할 수 있습니다.)
- 여기서 말하는 KEMI Poller의 동작방식은 카프카의 topic을 가지고 etcd에 저장된 메트릭정의를 통해 메트릭을 수집해오는 것인데, 일반적인 push방식이 아닌 polling 방식이며 이는 프로메테우스의 SNMP exporter를 사용하면 구현이 가능할 것으로 생각된다.
- 이 데이터들은 값을 그대로 이용할 수 있는 것(CPU usage 등)과 계산이 필요한 것(DISK usage 등)의 2종류가 있게 되며 samza를 이용한 KEMI의 Metric Calculator가 계산이 필요한 것은 계산을 해서 그 외는 그대로 다시 kafka에 넣게 됩니다.
- 메트릭이 어떻게 전달되며 이 데이터를 어떻게 필터링하여 계산이 필요한 데이터를 다시 전달하는지 구현을 고민해봐야 한다. (아마 해당 구분도 etcd에 지정해 놓고 활용할 것 같다 / 동적인 변화에 대응 가능)
poll 방식의 SNMP를 활용하기에 프로메테우스 같은 오픈소스를 사용하지 않고 단순히 메트릭을 etcd에 직접 정의하여 low 하게 수집해 오는 방식일 수도 있을 것 같으나
결국 데이터 메트릭을 opentsdb로 forward 시키는 것으로 보아 프로메테우스를 활용하는 것으로 예상해 볼 수 있다.
push 방식의 수집은 컨테이너 리소스 모니터링과 SNMP가 지원되지 않는 서버에서 사용되고 있으며 아래와 같은 순서로 실행
- 시간, 리소스 아이디, 시스템 메트릭을 KEMI의 Stats Agg로 push
- Rest API를 활용하므로 Agg가 백엔드 서버가 될 것이고, 해당 서버에서 수집된 내용을 API 형태로 호출하여 데이터를 전달하는 방식일 수 있을 것 같다.
- 의문점은 polling과 다르게 대상 서버 목록을 읽어오는 게 아니라는 것이다. 예상컨데, 스케일 인/아웃이 잦은 컨테이너 환경에 대한 정보라면 목록은 무시하고 마구 보내 대시보드가 동적으로 작동될 것 같긴 하다.
- KEMI의 Stats Agg에서는 이 메트릭들을 kafka에 저장합니다.
- 일부 계산이 필요한 메트릭은 polling방식과 마찬가지로 KEMI의 Metric Calculator에 의해 계산되어 저장되고 그 외 메트릭은 그대로 kafka에 저장됩니다.
SNMP가 지원되지 않는 서버라는 건 대표적인 게 컨테이너 환경을 말하는 것 같으며, Beat와 같은 오픈소스를 활용하면 해당 컨테이너들에 대한 메트릭을 push 방식으로 호출하여 데이터를 전송할 수 있을 것 같다.
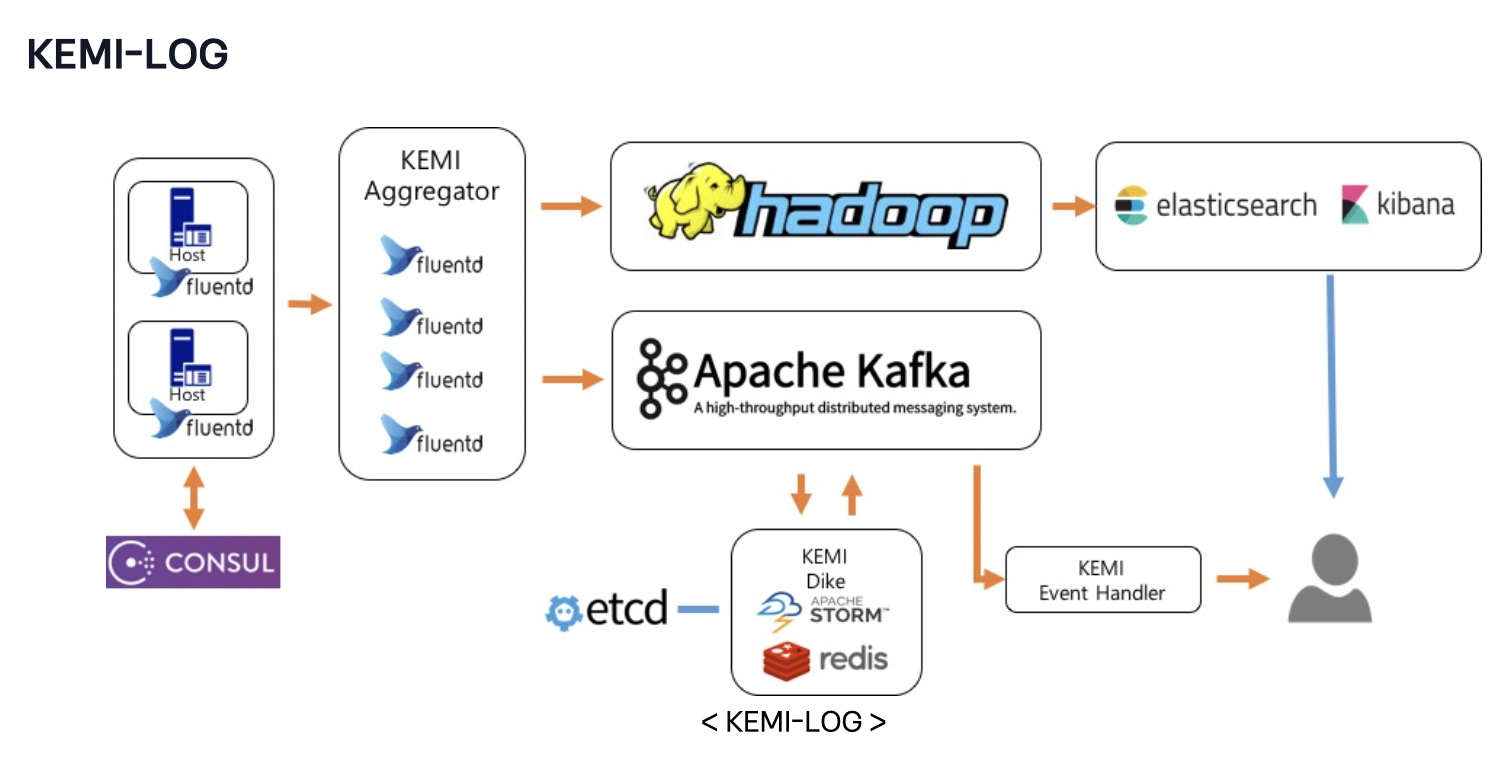
KEMI-LOG는 각 서비스에서 발생한 로그를 모아서 저장하고 보여주는 기능과 로그 별로 설정된 룰에 따라 알람을 발생시켜 줍니다. 인프라운영에 필요한 기본적인 syslog나 네트워크 관련 로그들을 받고 있으며, 필요에 따라 각 서비스들에서 KEMI-LOG 쪽으로 로그 데이터를 보내서 이용하고 있으며 그 규모는 하루 수백 기가 정도입니다
- 서비스 별 로그의 경우 각 서버에 설치된 fluentd를 이용하고 syslog나 네트워크 관련 로그는 syslog의 target 설정을 통해 consul domain으로 엮인 KEMI Aggregator로 전달됩니다.
- 구현방식은 모르겠으나, Aggregator 역할을 하는 서버 노드에 consul을 통해 fluentd서비스를 discovery 하여 로그 수집 대상을 관리하는 설명 같음
- 이렇게 보내진 데이터는 KEMI-LOG에 aggregator 역할을 해주는 fluentd 서버그룹들이 받은 다음에 그 로그들을 각각 hadoop, kafka에 넣어줍니다.
- hadoop에 저장된 데이터는 hive batch job을 통해 주기적으로 (5~15분) elasticsearch cluster로 indexing 되며 kibana를 통해 사용자가 조회할 수 있게 됩니다.
- kafka에 저장된 데이터는 etcd의 알람 룰과 STORM, redis를 활용해 개발된 KEMI Dike를 통해 실시간으로 알림을 발생시킵니다.
위 데이터 흐름에서 선택하거나 개발된 몇 가지 기술들과 방법은 아래와 같은 장점을 가집니다.
- fluentd는 다양한 플러그인들이 존재해서 간단한 설정만으로도 손쉽게 원하는 형태로 로그 데이터를 변환해서 주고받을 수 있습니다.
- 전체 aggregator 호스트를 service discovery 도구인 consul로 관리되는 도메인을 바라보게 되어 있어서, 각 서버에 있는 fluentd의 설정을 변경하지 않은 채로 KEMI Aggregator에 서버를 추가하거나 빼는 작업을 할 수 있어서 손쉬운 scale in/out이 가능합니다.
- hadoop의 안정적인 데이터 저장 제공으로 elasticsearch가 문제가 생겼더라도 재처리와 bulk insert로 인해 보다 많은 양의 로그를 indexing 처리할 수 있습니다.
- 로그 알림에 사용하는 rule은 표준 SQL 형식으로 사용자가 지정할 수 있고, rule을 etcd에 저장해 두기 때문에 storm topology의 재시작 없이 변경사항이 동적으로 적용됩니다.
- 발생한 알림은 커스텀 메트릭의 형태로 KEMI-STATS 쪽에 저장해서 대시보드를 구성해서 본다거나 KEMI-STATS과 KEMI-LOG의 통합 알림에도 사용할 수 있습니다.
Consul: Fluent-Bit가 Consul에 등록을 하게 되면, 서비스별로 로그 수집 Agent가 Live 한지 확인이 가능합니다. 방법으로는 주기적으로 HealthCheck 메시지를 보내어 로그 수집 Agent가 Live한지 체크합니다.
Prometheus: Consul을 이용하여 서비스별로 Live한 Agent 리스트를 찾아, 직접 Agent에 접근하여 Metric을 수집합니다. CPU/메모리 사용량, 수집된 로그의 IN/OUT 수치 등을 수집
출처: 멀티클라우드를 이용한 로그 분석 플랫폼 개발하기
로그 수집도 Aggregator를 둬서 역할을 분리한 구조 느낌을 받았고, 이 역시 프로메테우스로 해당 역할을 할 수 있을 것으로 예상된다.
서비스 디스커버리 오픈소스를 사용하여 동적으로 변화하는 서비스 목록을 한 곳에서 통합 관리가 가능하니 매우 유연한 확장이 가능할 것으로 보인다.
🔹 Fluentd의 주요 기능 feat Chatgpt
✅ 로그 수집
- 애플리케이션, 서버, 컨테이너 등 다양한 소스에서 로그를 수집
- tail, syslog, journald, http, tcp 등 다양한 입력 플러그인 지원
✅ 로그 변환 및 필터링
- JSON, CSV, XML 등 여러 형식의 데이터를 변환 가능
- 불필요한 로그 필터링 및 정제
✅ 로그 전달 (다양한 백엔드 지원)
- Elasticsearch, Kafka, Amazon S3, MongoDB, Prometheus 등으로 로그 전달 가능
✅ 경량 & 확장성
- Fluentd는 플러그인 기반 아키텍처로 필요에 따라 확장 가능
- Fluent Bit(경량 버전)도 제공
✅ 실시간 처리 & 버퍼링
- 스트리밍 방식으로 실시간 로그 처리
- 로그 손실 방지를 위해 메모리 또는 파일에 버퍼 저장
🔹 Consul의 주요 기능
- 서비스 디스커버리
- Consul은 네트워크 상의 서비스들을 자동으로 등록하고 검색할 수 있게 합니다.
- 클라이언트나 다른 서비스가 서버의 IP나 포트를 직접 알지 않아도, Consul을 통해 서비스를 쉽게 찾아 연결할 수 있습니다.
- 헬스 체크 (Health Check)
- Consul은 서비스가 정상적으로 작동하는지 주기적으로 헬스 체크를 실행하여 상태를 확인합니다.
- 비정상적인 서비스는 자동으로 서비스 디스커버리 목록에서 제외되어 장애 조치를 할 수 있습니다.
- 키-값 저장소
- 애플리케이션의 설정이나 기타 정보를 키-값 쌍으로 저장할 수 있는 저장소 기능을 제공합니다.
- 이를 통해 분산된 애플리케이션에서 설정 정보를 중앙에서 관리할 수 있습니다.
- 네트워크 분리 및 서비스 간 라우팅
- Service Mesh로서 애플리케이션 간 통신을 안전하게 처리하는데 중요한 역할을 합니다. (비밀정보 관리, 암호화 등)
- 이를 통해 서비스 간 인증, 권한 관리, 네트워크 제어 등이 가능합니다.
우아한 형제들 - ELK / E(elasticsearch) To L(Loki)로 전환기
https://techblog.woowahan.com/14505/
따끈따끈한 전사 로그 시스템 전환기: ELK Stack에서 Loki로 전환한 이유 | 우아한형제들 기술블로그
안녕하세요. 클라우드모니터링플랫폼팀의 이연수입니다. 우아한형제들의 모니터링시스템 구축 및 관리, 운영을 하고 있습니다. 작년부터 올해 초까지 팀에서 전사 로그 시스템을 전환을 진행
techblog.woowahan.com
해당 글에서는 전사 로그 시스템을 전환을 진행했던 계기와 전환 후 성과를 공유해 주셨습니다.
로그 시스템 관리와 운영이 길어지면 발생할 수 있는 문제점, 이에 대한 고민과 비용 절감에 대한 인사이트를 얻을 수 있었으며 추후 구축할 로그 시스템에서 용량이 커졌을 때를 고려해 볼 수 있을 것 같다.
로그 시스템은 항상 도전 과제를 안겨줍니다. 각 서비스에서 발생하는 대부분의 로그를 수집해야 하기 때문에 종류가 많고
비용이 많이 발생하지 않는지, 시스템 운영을 효율적으로 하고 있는지, 데이터를 효율적으로 저장하고 있는지 등 항상 풀어야 하는 숙제가 있습니다
로그 시스템은 High-Write, Low-Read 패턴으로 많은 데이터를 수집하지만 그에 비해 조회는 수집된 모든 데이터를 대상으로 하지 않습니다
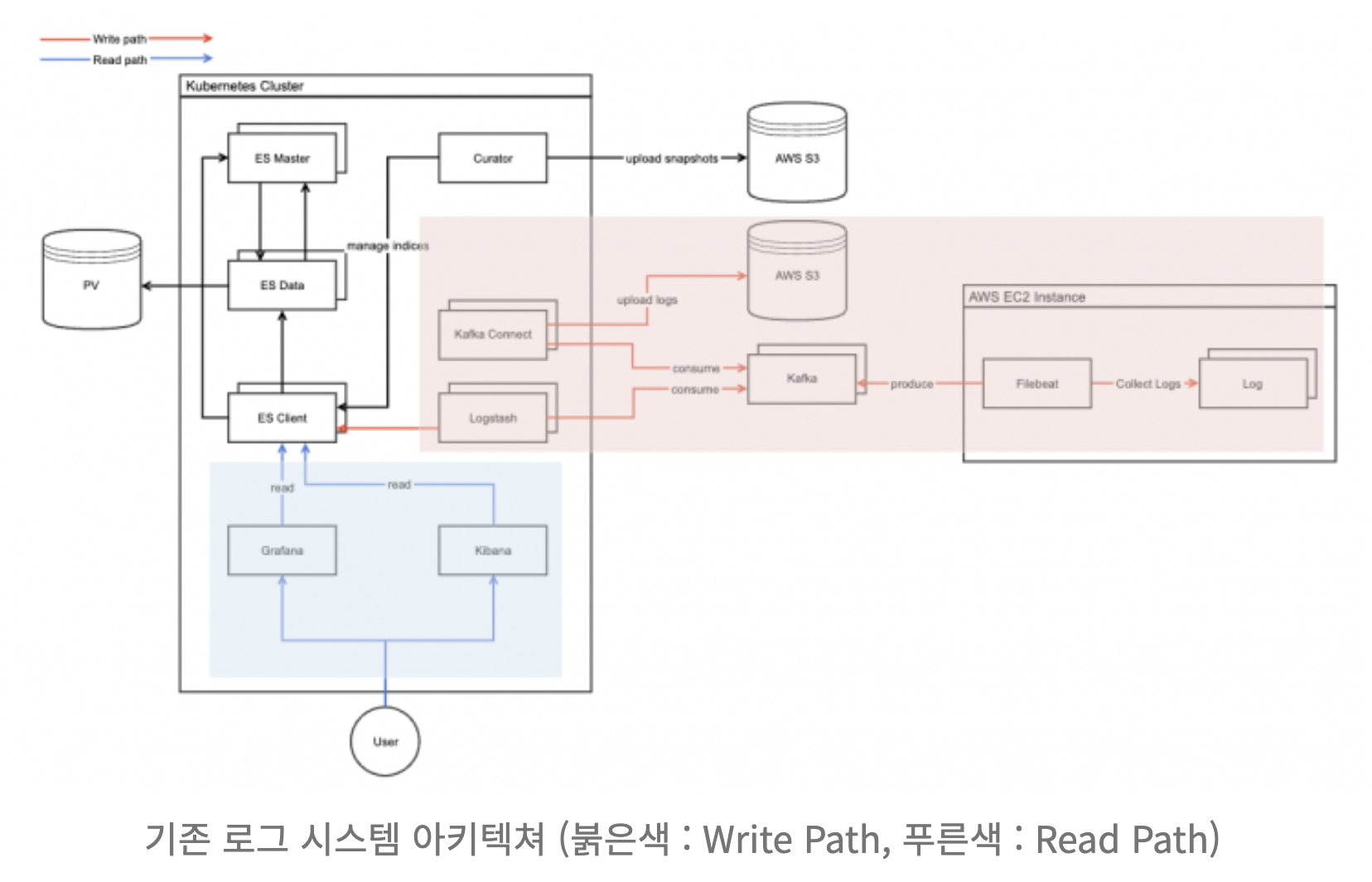
기존 로그 시스템은 ELK Stack을 사용하였고, 로그를 수집해 S3와 ES에 보관하는 형식이었으며 매일 밤 롤오버를 통해 인덱스 재구성 작업을 하여 성능을 유지하는 방식이었음
로그 수집 대상 확장과 로그 파일의 크기가 증가함에 따라 롤오버와 샤딩에 대해 성능 이슈가 발생
기존 로그 시스템의 문제
- 서비스 확장으로 인한 인덱스 부하가 발생했고 롤오버를 해도 인덱스 용량이 커져 클러스터 내 샤드의 수도 많아지는 등의 문제
- 부하 시 비정기적으로 클러스터 전체 API 접근이 실패하는 등 안정성 문제 발생 (치명적)
왜 해당 구조에서는 문제가 발생하는 것일까?
- PV와 오래된 로그 보관 S3 (PV에 용량이 증가하면서 클러스터 내 다른 서버에도 I/O 부하, S3에서 읽어와야 하는 데이터..)
데이터 저장소의 문제라고 판단된다. (스토리지를 사용했다면 스케일 업만 가능했을 것이며, 물리 PATH를 다른 클러스터 내 서버들과 공유하여 조회하는데 수집하는 곳에서 문제가 발생하는 것 예를 들면 timeout..)
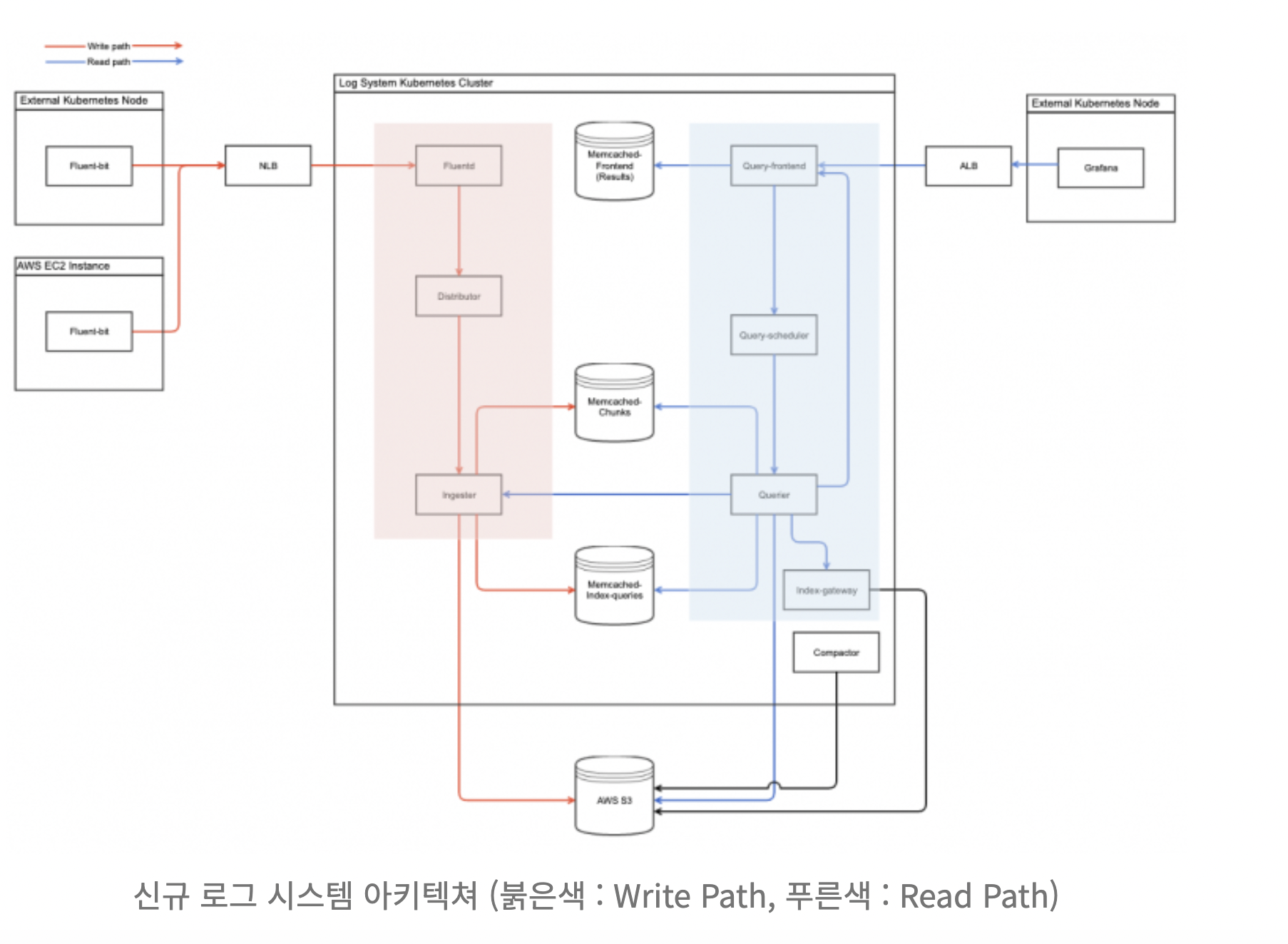
클라우드 플랫폼팀에서는 해당 오픈소스로 변경하였으며 이유는 위에서 설명했듯 다음과 같았습니다.
1. ES를 사용하려면 매일 밤마다 롤오버를 통해 인덱싱하여 검색 성능을 올리는데 오래된 로그들이 쌓여갈수록 오버헤드가 크며, 전체를 계속 활용하기엔 결국 비용 문제가 커짐 (ES의 높은 비용) => 오래된 로그도 보고 싶을 때가 있지만 큰 비용을 안기엔..
2. ES의 검색 때문에 클러스터 내 API들에 문제가 생기는 건 안정성에 문제가 있으며, 전파되는 건 아니라고 생각함 => 조회가 느렸으면 느린 걸 튜닝하면 되지만, 로그 수집 장애는 같이 발생하면 안 됨
ELK Stack에서 느끼는 한계와 이유들로 Grafana Loki로의 전환을 검토하게 되었습니다. Loki는 Grafana의 생태계인 LGTM(Loki, Grafana, Tempo, Mirmir)의 L을 담당하며 Prometheus에서 영감을 받아 개발된 수평 확장이 가능하고 가용성 높은 다중 테넌트 로그 집계 시스템입니다. 다른 로그 시스템과 달리 Loki는 로그에 대한 메타데이터만 인덱싱한다는 아이디어, 즉 레이블을 기반으로 구축되었습니다. 로그 내용을 색인화하는 것이 아니라 각 로그 스트림에 대한 레이블 세트를 색인화하기 때문에 레이블 단위로 로그는 별도로 압축되어 청크 단위로 저장이 되고 압축률에 따라 데이터가 감소 됩니다. 로그에 대한 메타데이터인 레이블을 인덱싱한다는 아이디어를 중심으로 구성이 되었고 로그를 조회하기 위해 먼저 레이블 기반으로만 조회를 하고 매칭되는 레이블들과 매칭된 압축 로그 데이터를 가져와서 사용자에게 보여줍니다.
- Loki는 단기간의 데이터만 메모리에 저장하고 나머지는 S3와 같은 오브젝트 스토리지에 저장하기 때문에 로그 수집량과 저장기간이 늘어날수록 리소스와 관리 비용이 늘어났던 Elasticsearch 대비 비용과 관리 측면에서 절감할 수 있을 것이라 기대 (1번 항목)
- 오브젝트 스토리지에 저장된 로그는 볼륨대비 비용이 적기 때문에 제한기간을 두지 않고 조회를 할 수 부분이 장점 (1번 항목)
- 수집, 조회 컴포넌트들이 구분되어 있어 이슈가 발생할 경우 특정 컴포넌트를 특정해서 조치할 수 있어 이슈 및 장애 조치도 쉬울 것이라 판단 (2번 항목)
우려 사항
- 풀텍스트 검색은 Elasticsearch에 비해 느린 부분, 쿼리 언어(LogQL)를 엔지니어들이 학습해야 하는 부분
- 학습을 통해 개선해 나가기