OS - Process Synchronization
본 글은 (KOCW) 운영체제, 이화여자대학교 반효경 교수님의 강의를 듣고 내용을 요약 및 정리했습니다.
스터디를 진행하는 것에 목적이 있으며, 자세한 사항은 여기를 참고하시면 됩니다.
데이터 접근

컴퓨터 시스템에서 데이터 연산은 저장 공간과 실행 공간이 아래와 같은 흐름으로 동작하며 이루어짐
- 저장 공간에 데이터가 있음
- 연산할 데이터를 실행 공간으로 가져옴
- 실행 공간에서 연산
- 연산 결과를 저장 공간에 반영
저장 공간은 메모리나 해당 프로세스의 주소 공간, 디스크 등이 있고 실행 공간은 CPU나 프로세스, 컴퓨터 내부 등이 있다
같은 데이터에 접근하여 연산하게 된다면 어떻게 처리되어야 할까?
Race Condition
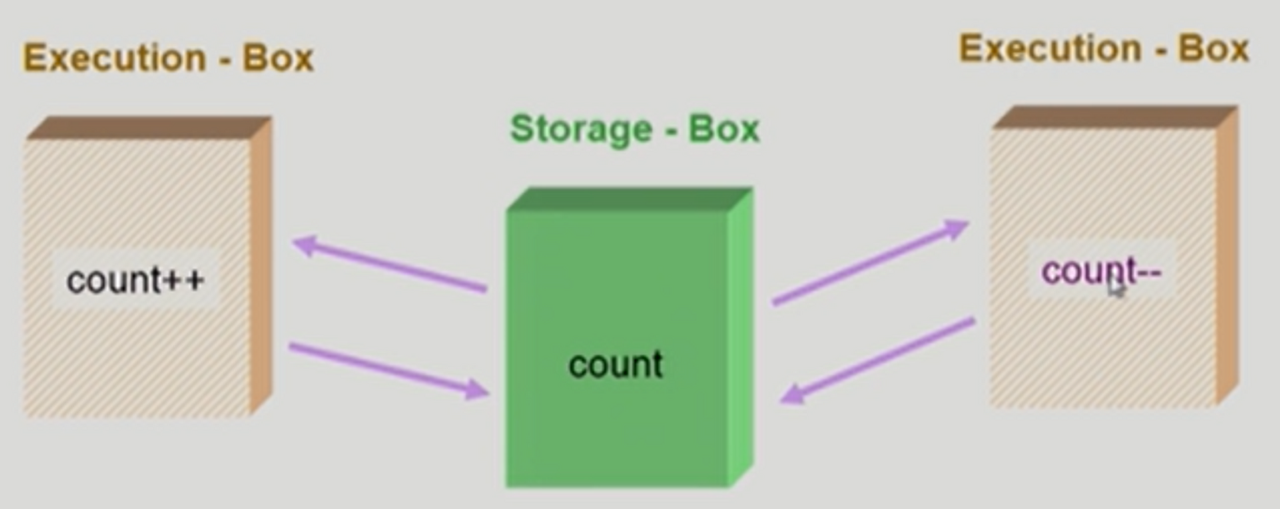
저장 공간을 공유하는 실행공간이 여러 개 있는 겨우 Race Condition의 가능성이 있다
예를 들어 메모리에 count 변수가 있고 서로 다른 CPU가 각각 증가, 감소 연산을 수행한다고 가정하면
- CPU A가 count 변수를 가져와 1 증가 후 메모리에 반영
- CPU B가 count 변수를 가져와 1감소 후 메모리에 반영
만약 CPU A, B가 동시에 count 변수를 가져와 연산 후 메모리에 반영하면? 마지막에 반영된 결과만 존재할 것 (count -1, count+1 둘 중 하나의 결과만 반영됨)
이 처럼 공유하는 하나의 주체에 여러 주체가 마치 경쟁하듯 접근하려 하는 것을 경쟁 상태 Race Condition이라고 한다
- 운영체제에서 Race Condition이 발생하는 상황
- 커널 수행 중 인터럽트 발생 시
- 프로세스가 시스템 콜을 호출하여 커널 모드로 수행 중인 가운데 context switching이 일어난 경우
- 멀티 프로세서에서 공유 메모리 내의 커널 데이터 접근
운영 체제에서의 Race Condition
인터럽트 핸들러 vs 커널

커널 모드가 수행 중인 상태에서 인터럽트가 발생하여 인터럽트 처리 루틴이 실행되는 상황
커널이 증감 연산을 할 때 메모리에서 count 변수를 load 하고, count 변수를 연산한 후 메모리에 다시 store 하는 3가지 연산이 발생
- load 연산을 수행한 후 증감 연산을 수행하기 전에 인터럽트가 들어왔다면?
- 인터럽트 핸들러를 통해 인터럽트를 수행할 것
- 인터럽트가 공유 변수인 count를 감소하는 연산이었고 인터럽트 이후 커널은 이전 연산을 이어감
- load했던 데이터는 인터럽트에 의한 연산이 반영되지 않았음
- count는 기존 값에서 1 증가한 결과만 반영이 되어버림
변수의 값을 건드리는 동안에 인터럽트가 발생해도 연산이 끝나고 수행될 수 있게끔 disable 처리를 해준다
커널 내에서 실행 중인 프로세스를 선점하는 경우

- 프로세스 A가 count 변수를 load 하고, 1 증가하기 위해 시스템 콜을 호출하여 커널 모드에서 작업을 처리하는 도중에 CPU 할당 시간이 끝나 context switch가 발생
- 프로세스 B가 CPU를 할당 받아 A와 동일하게 시스템 콜을 호출했고, count 변수를 1 증가하였다. 그리고 다시 context switch가 발생하여 프로세스가 A가 CPU를 잡아 count 변수를 1 증가
- count 변수 값이 2 증가해야 하는데 결과는 그렇지 않다. 프로세스 A는 프로세스 B가 증가 연산을 하기 전 count 값을 갖고 있었고, CPU를 다시 할당받았을 때 그 시점의 context를 가지고 값을 증가하였기 때문에 결과적으로 1만 증가
커널 모드에서 수행 중일 때는 CPU 할당 시간이 끝나도 선점하지 않고, 사용자 모드로 돌아갔을 때 선점
멀티 프로세서

CPU가 메모리에서 데이터를 가져 오기 전에 lock을 걸어 다른 CPU가 같은 데이터에 접근하는 것을 막아줌
연산이 끝난 후 데이터를 다시 메모리에 저장할 때 lock을 해제하여 다른 CPU가 접근할 수 있게 함
- 구현 방법1
- 한 번에 하나의 CPU만 커널에 들어갈 수 있게 함
- 커널 전체에 lock을 걸기 때문에 비효율적
- 구현 방법2
- 커널 내부에 있는 각 공유 데이터에 접근할 때마다 해당 데이터에 lock을 거는 방법
프로세스 동기화 문제
- 공유 데이터의 동시 접근은 데이터의 불일치 문제를 유발할 수 있음
- 일관성 유지를 위해서는 협력 프로세스 간의 실행 순서를 정해주는 메커니즘이 필요
- Race Condition
- 여러 프로세스들이 동시에 공유 데이터를 접근하는 상황
- 데이터의 최종 연산 결과는 마지막에 그 데이터를 다룬 프로세스에 따라 달라짐
- Race Condition을 막기 위해서는 병행(Concurrent) process는 동기화되어야 함
임계 구역 문제(The Critical-Section Problem)
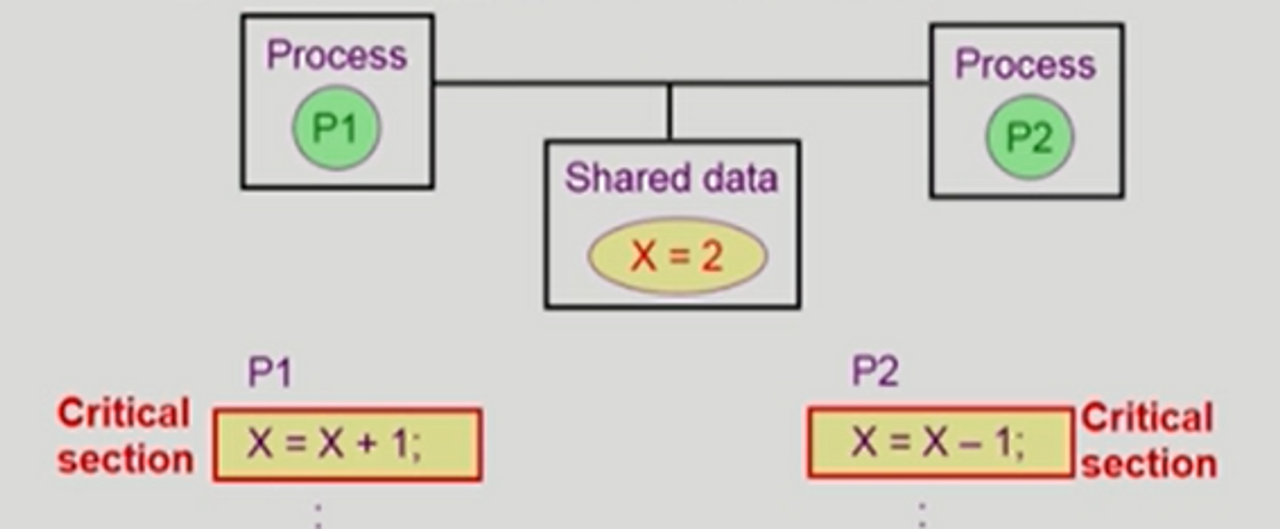
- n개의 프로세스가 공유 데이터를 동시에 사용하기를 원하는 경우 각 프로세스의 Code Segment에는 공유 데이터를 접근하는 코드인 임계구역이 존재
- 하나의 프로세스가 임계 구역에 있을 때 다른 모든 프로세스는 임계 구역에 들어갈 수 없어야 함
임계 구역 문제를 해결하기 위한 충족 조건
- 상호 배제 (Mutual Exclusion)
- 어떤 프로세스가 임계 구역 부분을 수행 중이면 다른 모든 프로세스는 그의 임계 구역에 들어가면 안 된다
- 진행 (Progress)
- 아무도 임계 구역에 있지 않은 상태에서 임계 구역에 들어가고자 하는 프로세스가 있으면 임계 구역에 들어가게 해 주어야 한다
- 유한 대기 (Bounded Waiting)
- 프로세스가 임계 구역에 들어가려고 요청한 후부터 그 요청이 허용될 때까지 다른 프로세스들이 임계 구역에 들어가는 횟수에 한계가 있어야 한다
- e.g 세 개의 프로세스가 있을 때 두 개의 프로세스만 번갈아가며 임계 구역에 들어가는 것은 유한 대기 조건을 만족하지 못한 것
해당 조건은 모든 프로세스의 수행 속도는 0보다 크며, 프로세스 간의 상대적인 수행 속도는 가정하지 않음
임계 구역 문제 해결 알고리즘
Algorithm1
Synchronization variable
int turn;
initially turn = 0; // 몇 번 프로세스가 들어갈 수 있는지를 알려주는 turn 변수
Process P0
turn 변수가 0이 아닌 동안 while문을 계속 돌면서 자기 차례를 기다림
do {
while (turn != 0);
critical section
turn = 1;
remainder section
} while (1);
- 상호 배제(mutual exclusion)는 만족하지만 진행(Progress)은 만족하지 못함 -> 한 번씩 교대로 임계 구역에 들어가야 하기 때문 (나 다음 turn = 1이라는 건 1번 프로세스..)
- P0는 임계 구역에 5번 들어가야 하고 P1은 한 번만 들어가면 되는 상황에서 P1은 한 번 임계구역에서 처리하면 끝이지만 P0는 P1이 다시 들어갈 때까지 본인도 못 들어가므로 Progress 조건이 성립되지 않음 (과잉양보)
Algorithm2
Synchronization variable
boolean flag[2];
initially flag[모두] = false; // critical section에 들어가고자 하는 의사 표시Process Pi
do {
flag[i] = true;
while (flag[j]);
critical section
flag[i] = false;
remainder section
} while (1);상대방이 임계 구역에 들어가 이지 않고, 들어갈 준비도 하지 않는다면 본인이 들어감
세 가지 조건을 모두 만족(Mutual Exclusion, Progress, Bounded Waiting)
계속 CPU와 메모리를 쓰면서 기다리기 때문에 Busy waiting(spin lock)이 발생
-> 임계 구역에 들어가려면 다른 Process가 CPU를 잡고 flag 변수를 false로 바꿔주어야 하는데, 내가 CPU를 잡고 있는 상황에서 의미 없이 while문을 돌며 CPU할당 시간을 낭비해야 한다
동기화 하드웨어
임계 구역 문제가 발생한 근본적인 이유는 데이터를 읽고 스는 동작을 하나의 명령어로 수행할 수 없기 때문
명령어 하나만으로 데이터를 읽는 작업과 쓰는 작업을 atomic 하게 수행하도록 지원하면 앞선 임계 구역 문제를 간단하게 해결할 수 있음

-> a 변수를 읽은 후 그 변수를 무조건 1로 설정하도록 명령어 구성 (atomic)
Mutual Exclusion With Test & Set
Synchronization variable
boolean lock = false;Process Pi
do {
while (Test_and_Set(lock));
critical section
lock = false;
remainder section;
} while (1);Test_and_Set() 함수는 매개 변수를 읽어내고, 그 변수를 1로 바꿔 주는 역할을 한다. 위 예시에서 lock을 읽고 난 뒤 1로 바꿔준다
만약 처음에 lock의 값이 0이었다면, while문을 탈출하고 lock 값이 1이 된다. 반대로 lock의 값이 1이면 while문에서 갇히고 lock 값은 그대로 1이 된다
세마포어
임계구역에 대한 문제점을 해결하기 위한 알고리즘을 살펴보았는데 단일 자원이 아닌 좀 더 넓은 상황에서 특정 리소스에 대해 액세스 여부를 제어하는 세마포어에 대해 알아보자
Integer variable
- S를 사용
아래의 두 가지 atomic 연산에 의해서만 접근 가능
- P(S): 공유 데이터르 획득하는 과정(lock)으로 S가 양수여야 한다
// P(S)
while (S <= 0) do no-op; // ex) wait.
S--;- V(S): 공유 데이터를 사용하고 반납하는 과정(unlock)
// V(S)
S++;n개의 프로세스가 임계 구역에 들어가려는 경우
Synchronization variable
semaphore mutex;Process Pi
do {
P(mutex); // mutex의 값이 양수면 임계 구역 접근하고, 아니면 기다린다.
critical section
V(mutex); // mutex의 값을 1 증가한다.
remainder section
} while (1);
P(mutex) 연산 수행 시, mutex의 값이 양수가 아니면 계속 기다려야 하는데, 프로세스의 CPU 할당 시간이 끝날 때까지 무의미하게 CPU를 낭비하는데, 이러한 현상을 busy-wait 또는 spin lock이라고 부른다
이러한 단점을 보완하기 위해 Block & Wake-up 혹은 Sleep lock이라고 부르는 기법이 생김
Block / Wake-up 기법
Synchronization variable
typedef struct
{
int value; // 세마포어 변수
struct process *L; // 프로세스 Wait Queue
} semaphore;
- block
- 커널은 block을 호출한 process를 suspend 하고 이 프로세스의 PCB를 세마포어에 대한 Wait Queue에 넣음
- wakeup(P)
- block 된 process P를 wake up 하고 이 프로세스의 PCB를 Ready Queue로 옮김
세마포어 연산을 다음과 같이 정의
// P(S)
S.value--;
if (S.value < 0)
{
add this process to S.L;
block();
}- P(S): 세마포어 변수 S를 무조건 1줄이고, 그 변수의 값이 음수면 해당 프로세스를 Wait Queue로 보낸 후 Block 상태로 만듦
// V(S)
S.value++;
if (S.value <= 0)
{
remove a process P from S.L;
wakeup(P);
}- V(S): 세마포어 변수 S를 무조건 1 늘리고, 변수의 값이 0보다 작거나 같으면 이미 기다리고 있는 프로세스가 있으므로 Process P를 Wait Queue에서 꺼내서 Ready Queue로 보냄
- 세마포어 변수 S값이 양수면 아무나 임계 구역에 들어갈 수 있으므로 별다른 추가 연산을 하지 않음
- V연산은 특정 프로세스가 공유 데이터를 반납한 후 임계 구역에서 나가는 연산임을 기억해야 함
- 나 이제 임계구역에서 나갈 거니까 기다리는 친구 있으면 임계 구역에 들어가!
Busy wait vs Block/Wake-up
- 일반적으로 Block Wake-up 기법이 좋음
- 임계구역의 길이가 긴 경우 Block/Wake-up 기법이 적합
- 임계구역의 길이가 매우 짧은 경우 Block/Wake-up 기법의 오버헤드가 Busy-wait 기법의 오버헤드보다 크므로 Busy wait기법이 적합할 수 있음
세마포어 종류
- 계수 세마포어(Counting Semaphore)
- 도메인이 0 이상인 임의의 정수 값
- 여러 개의 공유 자원을 상호 배제함
- 주로 resource counting에 해당
- 이진 세마포어(Binary Semaphore)
- 0 또는 1 값만 가질 수 있음
- 한 개의 공유 자원을 상호 배제함
- mutex와 유사함 (완전 같지는 않다)
Deadlock과 Starvation
- Deadlock
- 둘 이상의 프로세스가 서로 상대방에 의해 충족될 수 있는 event를 무한히 기다리는 현상
- 예시

P0가 CPU를 얻어서 P(S) 연산까지 수행하여 S 자원을 얻었다고 가정
- P0의 할당 시간이 끝나 Context Switching이 발생하여 P1에 CPU가 넘어감
- P1은 P(Q) 연산을 수행하여 Q 자원을 얻었으나 CPU 할당 시간이 끝나 Context Switching이 발생하여 P0에 CPU가 넘어감
- P0는 P(Q) 연산을 통해 Q자원을 얻고 싶으나 P1이 이미 갖고 있으므로 얻지 못함
- P1은 P(S) 연산을 통해 S자원을 얻고 싶으나 P0가 이미 갖고 있으므로 얻지 못함
- 영원히 P0와 P1은 서로의 자원을 가져올 수 없음 -> Deadlock 상황
해결방안?
- 자원의 획득 순서를 정해줘 S를 획득해야만 Q를 획득할 수 있게끔 순서를 정해준다
- P0가 S를 획득했을 때 P1이 Q를 획득할 일이 없다
Starvation (기아 상태)
- indefinite blocking 상태를 의미
- 프로세스가 자원을 얻지 못하고 무한히 기다리는 현상
Deadlock vs Starvation
둘 다 자원을 얻지 못하고 무한히 기다린다?는 혼동이 생길 수 있음
- Deadlock은 P0가 A 자원을 보유하고 있고 P1이 B 자원을 보유하고 있을 때 서로의 자원을 요구하며 무한히 기다리는 현상
- Starvation은 프로세스가 자원 자체를 얻지 못하고 무한히 기다리는 현상
- 어떤 프로세스가 자원이 없어서 굶어 죽는다