본 내용은 인프런 김영한 님의 강의 실전! 스프링 부트와 JPA 활용 2를 바탕으로 작성한 내용입니다.
주문 내역을 확인해서 배송 정보, 회원 정보까지 확인하는 API를 만들어본다.
주문 내역에 대한 엔티티 설계는 다음과 같고, 주문 엔티티가 연관관계의 주인이 되는 경우 모두 지연 로딩을 설정했다.

조회 성능을 최적화하기 위해 초기 데이터를 삽입하였다.
- UserA(주문 회원)
- JPA1 BOOK (주문 상품)
- JPA2 BOOK (주문 상품)
- UserB(주문 회원)
- SPRING1 BOOK (주문 상품)
- SPRING2 BOOK (주문 상품)
이제 본격적으로 V1~V4까지 API 버전을 바꿔가며 지연로딩으로 인해 발생하는 성능 문제를 어떻게 해결해나가는지 학습하겠습니다.
V1 : 엔티티를 직접 노출
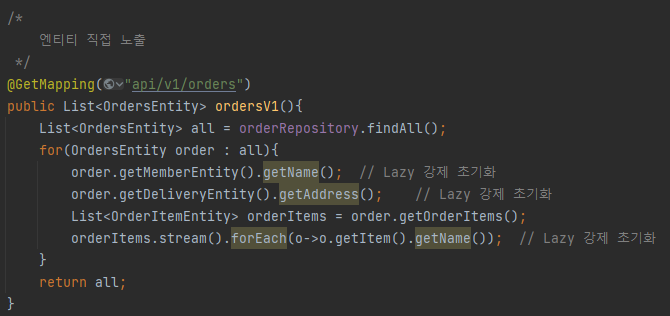
지연 로딩을 하게되면 프락시 객체를 가져오게 되는데, get 메서드를 통해 초기화를 시켜서 영속성 콘텍스트에 등록한다.
하지만 Member와 Order가 양방향 관계이면 Member에 있는 order를 참조하고 order의 member를 다시 참조하기 때문에 무한루프의 문제가 발생한다. 실제로 그냥 실행해보면 같은 데이터가 계속 반복해서 나타나며 터미널에 databind와 관련된 에러가 나타났다(Postman에선 에러가 발생하며 실행이 안됨)

. 이러한 문제는 연관관계가 있는 엔티티들 중 한쪽에 @JsonIgnore를 주어야 하는데 이렇게 API에 따라 엔티티에 무언가를 추가하고 수정하는 방식은 올바르지 못하다.
정 엔티티를 직접 노출하면서 API를 설계할 것이라면 연관관계가 있는 한 곳을 @JsonIgnore 처리를 해주자.

기본적으로 jackson 라이브러리는 프락시 객체를 json으로 어떻게 생성해야 하는지 모른다고 한다. 따라서 그냥 실행해버리면 지연 로딩에 의한 프락시 객체 생성에서 예외가 발생한다.
이를 해결하기 위해 Hibernate5Module을 스프링 빈으로 등록하면 된다고 함..
연관관계가 있는 엔티티들에 JsonIgnore를 추가해주고 Hibernate5 Module을 스프링 빈에 등록했더니 무한루프에 걸리지 않고 작동은 한다. 하지만 엔티티들을 너무 많이 수정했고 다른 API에서도 같은 엔티티를 사용하면 문제가 발생할 수도 있게 된다.
엔티티를 직접 노출하는 것은 내 개인적인 생각으로도 절대 안 됨!
V2 엔티티를 DTO로 변환

엔티티를 DTO로 변환하는 일반적인 방법이다. 엔티티를 조회한 후, 필요한 데이터만 생성자를 통해 생성하여 사용한다.

원하는 데이터가 잘 출력이 되었다. 하지만 여기서 터미널에 출력되는 쿼리문들을 봐야 할 필요가 있다.
엔티티를 DTO로 변환하여 데이터를 뽑아오는 방법은 일반적이고 올바르다고 생각한다. 하지만 여기서는 지연 로딩 때문에 쿼리 성능에 문제가 발생한다. 흔히 n + 1 문제라고 언급되는 문제가 발생하는 것이다.
여기서는 Member가 UserA, UserB로 두 명, 주문 상품인 orderItem은 각각 두 개씩 주문하였지만 Delivery는 하나의 배송이 된다. 따라서 order 조회 쿼리 1번에 지연 로딩에 의한 Member 조회 쿼리, Delivery 조회 쿼리가 각 n번씩 추가로 발생하게 되는 것이다.

V2 API를 실행하면서 날린 쿼리를 확인해보면 최악의 경우 1 + 2 + 2의 쿼리가 발생한다. 그래서 1 + n 문제라고 생각한다고.. 합니다.
V3 : 엔티티를 DTO로 변환 - fetch join 최적화
V2에서는 일반적인 join을 이용해 엔티티를 영속화하고, 필요한 엔티티들을 지연 로딩에 따라 영속화하는데
Order를 조회할 때 Member와 Delivery의 데이터가 항상? 거의 필요한 상황이라면 쿼리 한 번에 조회하여 성능을 최적화할 수 있다는 것이 fetch join입니다.
api는 V2와 거의 동일하나 날리는 쿼리에 fetch join을 사용하여 join 하는 모든 엔티티를 한번에 영속화합니다.


V2 API와 같은 결과가 조회되며 쿼리를 살펴보면

조금 지저분할 수 있지만 쿼리 1개로 엔티티를 모두 조회(객체 그래프 탐색 방식) Member, Delivery는 이미 조회된 상태 이므로 지연 로딩되지 않음.
엔티티들을 조회하는 과정에서 꼭 필요한 엔티티만 영속화하는 게 옳다고 생각하기 때문에, 만약 모든 엔티티의 데이터가 다 필요한 게 아니라면 전부 fetch join 할 필요가 없다. 일반 join을 잘 활용해야 함.
한 번에 조회하기 때문에 모든 쿼리 성능을 최적화할 수 있는데 왜?라고 생각할 수 있지만
필요하지 않은 엔티티까지 영속성 콘텍스트에 올려버리면 DB와 객체 사이의 일관성이 깨지는 문제가 발생할 수도 있지 않을까라고 생각하면 좋을 것 같다. 따라서 적절히 join과 fetch join을 고려해서 사용하자..
V4 : JPA에서 DTO로 바로 조회
V3를 보면 조회하는 쿼리가 엔티티의 모든 속성들을 조회하기 때문에 쿼리가 지저분해 보인다. 이를 JPA에서 DTO로 바로 조회하도록 변경하게 되면 필요한 데이터만 조회할 수 있기 때문에 성능이 조금 더 최적화된다. (실제 미비하다고 함)
이렇게 하기 위해서는 API에 따라 쿼리를 커스텀해서 사용해야 하기 때문에 쿼리를 날리는 Repository의 재사용성이 떨어진다.

쿼리가 보기에 간단해졌고 어떤 데이터를 필요로 하는지 확인하기 쉬워졌다. 하지만 생각보다 미비한 네트워크 용량 최적화에 비해 재사용성이 떨어지고 패키지 관리도 복잡해진다는 것은 유지보수 측면에서 크게 작용한다고 생각되어 아직 나는 개인적으로 사용하지 않을 것 같다..
김영한 님의 강의에서 권장하는 방법
1. 우선 엔티티를 DTO로 변환하는 방법을 선택한다.
2. 필요하면 페치 조인으로 성능을 최적화한다. -> 대부분의 성능 이슈가 해결된다.
3. 그래도 안되면 DTO로 직접 조회하는 방법을 사용한다.
4. 최후의 방법은 JPA가 제공하는 네이티브 SQL이나 스프링 JDBC Template을 사용해서 SQL을 직접 사용한다.
지금까지 xToOne 관계에서 조회 성능 최적화를 알아보았다..
처음 Order 엔티티 설계를 보면 List로 이루어진 orderItems가 존재하는데 이러한 컬렉션을 조회하는데 발생하는 성능 이슈를 공부해보고 또 글을 남기도록 하겠다
제 개인적인 생각이 들어가면서 정리한 글이기 때문에 문제점, 지적 댓글 주시면 감사합니다!!
'JPA' 카테고리의 다른 글
| Querydsl을 이용한 Cursor기반 페이징 API 구현 과정 (2) | 2022.12.11 |
|---|---|
| Entity와 DTO의 분리 (0) | 2022.07.06 |

