글을 작성하는 도중 인덱스에 대한 개념부터 알아두어야 이해가 더 쉬울 것 같아 글을 분리하였습니다
1편은 여기를 참고해 주세요!
대부분의 개발자들은 대용량 서비스에서 어떻게 데이터베이스의 부하를 줄이고 성능을 올릴 수 있는지에 대해 고민하고 여러 방법을 테스트해 볼 것이다.
나도 자주 고민해 봤지만 부하 테스트 환경 세팅, 서비스 구조, DB 구조에 따라 적용해 볼 수 있는 방법이 모두 다르며 제 각각의 상황에 맞는 고민을 하기 때문에 쉽게 접근해보지 못하였다.
이에 따라 사이드 프로젝트로 이커머스 도메인에서의 대용량 시스템일 때 어떤 기술들을 적용해서 성능을 최적화시킬 수 있을지 여러 방면으로 테스트하고 변화를 확인해 보는 프로젝트를 진행해 볼까 생각하고 있다.
이에 대한 사전 공부로 회원이 작성한 게시글을 조회할 때 100만 건 이상의 게시글을 가지고
- 어떤 필드에 인덱스를 적용하느냐에 따라 어떤 변화가 있을지
- 데이터 분포에 따른 인덱스 적용
을 확인해보고자 한다.
이에 앞서 인덱스가 왜 읽기 성능 향상에 좋은 것(항상 좋다고 할 순 없다)인지 부터 인덱스 적용 테스트까지 순차적으로 알아보고자 한다.
인덱스를 사용하면 빨라질 수도 있고, 상황에 따라 느려질 수도 있다는 것은 대부분의 개발자가 알고 있을 것이다.
나도 그렇지만 어떤 상황에서? 왜? 성능이 달라지는가를 설명하기엔 지식이 부족하여 자세히 알아보고자 한다.
이 글은 MySQL-8.0 버전을 기준으로 작성했습니다
데이터베이스 성능
인덱스를 사용하는 이유가 무엇인가?
쓰기 비용을 지불하고 읽기 성능을 올리는 방식으로 범위 탐색에 용이하다는 것을 기본으로 알고 있을 것이다.
왜 인덱스를 사용하면 성능 향상 효과를 볼 수 있을까?
데이터베이스에서 데이터를 조회하는 방식을 먼저 살펴보자.

데이터베이스에 보관되는 데이터는 메모리 혹은 디스크에 보관되며 최종적으로 디스크에 데이터가 저장될 것
메모리에 접근하는 것보다 디스크 I/O에 접근하는 것이 비용이 훨씬 크고 느리다는 것을 알고 있을 것이다.
쉽게 정리하면
데이터베이스의 성능은 디스크 I/O의 접근을 최소화하는 것으로 성능 향상을 기대할 수 있다고 생각할 수 있다
그렇다면 디스크 I/O의 접근을 최소화하는 방법은 무엇이 있을까?
MySQL의 데이터가 저장되는 Tablespace를 먼저 보자

핵심만 보면 결국 페이지 단위의 row 데이터를 읽게 되는 것이다.
캐싱의 성능은 무엇이 결정한다고 생각할 수 있을까?
메모리에 올라온 데이터로 최대한 요청을 처리하는 것
--> 메모리 캐시 히트율을 높이는 것
같은 원리로 적은 디스크 I/O를 발생시키려면?
우리가 탐색할 데이터가 있는 페이지 조회 히트율을 높이면 된다
중간 정리를 하면
- 데이터베이스의 데이터가 저장되어 있는 디스크 I/O가 성능 저하의 원인
- 디스크에 접근하지 않고 메모리에 저장함으로써 데이터를 조회하면 더 빠르며 대표적인 예시가 캐싱임
- 캐싱의 성능을 생각해 보면 메모리 캐시 히트율을 높여서 디스크의 접근을 최소화하는 것
- 같은 원리로 우리가 탐색할 데이터가 있는 페이지 조회 히트율을 높이는 방법을 활용해 볼 수 있다(Index Range Scan)
데이터 접근 방법
인덱스를 사용하는 데이터 스캔 방식과 아닌 방식의 차이는 다음과 같다.
Table Full Scan
- 테이블의 전체 데이터를 처음부터 끝까지 순차적으로 읽는 방식
Index Range Scan
- 인덱스를 사용하여 특정 범위의 데이터를 선택적으로 읽는 방식
- 인덱스 범위를 따라 필요한 블록만 디스크에서 읽어오는 방식
위의 내용만 보면 무조건 Index Range Scan이 좋아 보인다.
하지만 MySQL에서는 Single Block I/O, Multi Block I/O, Buffer Pool 등 을 지원하면서 여러 방면에서 생각해야 한다.
간단한 예시로만 살펴보고 후에 테스트를 통해 확인해 보도록 한다.
Single Block I/O
- 디스크에서 한 번에 하나의 데이터 블록만 읽거나 쓰는 방식
- 각각의 쿼리나 트랜잭션이 필요한 데이터 블록을 읽거나 쓸 때, 해당 블록만 디스크에서 읽거나 쓰게 되며 이는 일련의 작은 작업에 적합
Multi Block I/O
- 디스크에서 한 번에 여러 데이터 블록을 읽거나 쓰는 방식
- 데이터를 한꺼번에 더 많이 읽거나 쓸 수 있어서 데이터베이스의 읽기/쓰기 성능을 향상시킬 수 있음
- 대용량 데이터 처리나 범위 스캔 작업과 같이 대량의 데이터를 처리해야 할 때 효과적
Buffer Pool
- Innodb 엔진에서 테이블이나 인덱스 데이터를 캐시 하는 메모리 영역
상황 예시
- 적은 범위의 데이터를 조회할 때는 인덱스를 활용한 탐색과 Single Block I/O가 효과적일 수 있다.
- 범위 스캔 시에는 Multi Block I/O를 통해 여러 블록을 한 번에 읽어 스캔하면 더 효과적일 수 있다.
- 상황에 따라 Buffer Pool에 해당 데이터 블록이 캐시 되어 있다면 Multi Block I/O로 메모리 캐시를 스캔
Single Block과 Multi Block은 옵티마이저가 선택한다.
-> 잘못된 선택을 하게 될 수 있음 (Hint 사용이 필요할 수 있음)
- 옵티마이저는 각 쿼리에 대해 쿼리 조건, 인덱스 특성, 테이블의 크기 등을 고려하여 최적의 실행 계획을 결정
간단하게 고민해 볼 수 있는 부분
- 하나의 레코드의 크기가 커서 Buffer Pool에 저장되는 페이지의 수가 적다면? 스캔 범위가 비슷한 상황에서 어떤 방식이 성능에 우위를 점유하는지는 QA를 통해 항상 분석해봐야 할 것
더미 데이터를 활용한 인덱스 성능 테스트
100만 건의 데이터를 생성하여 인덱스를 활용했을 때 어떤 이점이 있는지 어떤 상황에 적합한지 알아보자
테스트에 앞서 어떤 테이블을 생성할지를 보자
간단한 Post 테이블을 먼저 생성한다
create table POST
(
id int auto_increment,
memberId int not null,
contents varchar(100) not null,
createdDate date not null,
createdAt datetime not null,
constraint POST_id_uindex
primary key (id)
);
easyrandom을 통해 랜덤 데이터 생성 방식 확인
EasyRandomParameters parameters = new EasyRandomParameters()
.seed(123L)
.objectPoolSize(100)
.randomizationDepth(3)
.charset(forName("UTF-8"))
.timeRange(nine, five)
.dateRange(today, tomorrow)
.stringLengthRange(5, 50)
.collectionSizeRange(1, 10)
.scanClasspathForConcreteTypes(true)
.overrideDefaultInitialization(false)
.ignoreRandomizationErrors(true);
EasyRandom easyRandom = new EasyRandom(parameters);timeRange, DateRange, collectionSizeRange 등 여러 파라미터를 통해 랜덤 하게 생성하여 데이터 분포를 분산시킬 수 있음
랜덤하게 사용하기 싫은 필드가 있을 경우 randomize를 통해 필드를 주입할 수도 있고, 제외시킬 수도 있다
EasyRandomParameters parameters = new EasyRandomParameters()
.randomize(String.class, () -> "foo")
.excludeField(named("age").and(ofType(Integer.class)).and(inClass(Person.class)))
// set other parameters
.build();
EasyRandom easyRandom = new EasyRandom(parameters);
Person person = easyRandom.nextObject(Person.class);EasyRandom이라는 라이브러리를 사용해서 더미 데이터를 만들고 테이블에 인덱스를 적용하여 테스트를 진행한다
위의 예시를 통해 EasyRandom 객체를 반환하는 코드는 다음과 같다
public static EasyRandom get(Long memberId, LocalDate start, LocalDate end) {
// 파라미터 만들기
EasyRandomParameters parameter = getEasyRandomParameters();
parameter
.randomize(memberId(), () -> memberId)
.randomize(createdDate(), new LocalDateRangeRandomizer(start, end));
return new EasyRandom(parameter);
}
private static EasyRandomParameters getEasyRandomParameters() {
return new EasyRandomParameters() // id는 제외 auto increment
.excludeField(named("id"))
.stringLengthRange(1, 100)
.randomize(Long.class, new LongRangeRandomizer(1L, 100000L));
}
private static Predicate<Field> memberId() { // memberId는 Predicate 타입으로 주입
return named("memberId").and(ofType(Long.class)).and(inClass(Post.class));
}작성한 테스트 코드
@SpringBootTest
public class PostBulkInsertTest {
@Autowired
private PostRepository postRepository;
@Test
public void bulkInsert() {
/*
TODO: 병목지점이 무엇인지 확인해보고 개선방안을 생각해보자
*/
var easyRandom = PostFixtureFactory.get( // easyrandom 객체 생성
1L,
LocalDate.of(2022, 1, 1),
LocalDate.of(2022,2,1)
);
var stopWatch = new StopWatch();
stopWatch.start();
int _1만 = 10000;
var posts = IntStream.range(0, _1만 * 100)
.parallel() // 병렬처리
.mapToObj(i -> easyRandom.nextObject(Post.class))
.toList();
stopWatch.stop();
System.out.println("객체 생성 시간: " + stopWatch.getTotalTimeSeconds());
var queryStopWatch = new StopWatch();
queryStopWatch.start();
postRepository.bulkInsert(posts); // save를 한 번에 묶어서 쿼리를 보냄
queryStopWatch.stop();
System.out.println("DB 인서트 시간: " + queryStopWatch.getTotalTimeSeconds());
}
}그럼 테스트를 실행하여 데이터 insert에 대한 시간을 측정해 보자 이때 top 명령어로 mysql에 insert 할 때 CPU와 Memory가 얼마나 튀는지 확인해 보았다


CPU의 순간 부하가 100을 넘어가기도 하고 메모리도 엄청난 부하가 생긴다(함부로 더미 데이터 쌓다가 컴퓨터가..)
이번에는 인덱스를 알아보기 위한 테스트로 최적화 없이 그냥 진행하였지만 API 부하 테스트로 진행해 본다던지, 최적화를 진행해본다던지 여러 발생할 수 있는 병목지점을 알아보며 테스트하는 것도 또 하나의 숙제가 될 것 같다
일반적인 Select문을 통해 걸리는 시간과 explain을 통해 옵티마이저가 선택한 전략에 대해 확인해 보았다


결과를 보면 Type이 ALL로 Full Table Scan이 일어날 때 838ms가 걸렸고 총 290만 개의 데이터를 스캔했다
이번에는 인덱스를 추가하여 테스트를 해보자
create index POST__index_member_id
on POST (memberId);
create index POST__index_created_date
on POST (createdDate);
create index POST__index_member_id_created_date
on POST (memberId, createdDate);적용하게 되면 역시나 CPU가 엄청 튄다.. 300만 건에 대한 인덱스 테이블을 생성하기 때문에.. 비용이 크다

인덱스가 잘 생성되었고 다시 쿼리를 날리는데, 명확하게 인덱스를 탈 수 있도록 `use index`로 인덱스를 강제한다
0. Full Table Scan - 838ms
1. memberId 인덱스 활용 - 1s 546ms

2. createdDate 인덱스 활용 - 9s

3. memberId, createdDate 복합 인덱스 활용 - 402ms

결과
- MemberId, createdDate 인덱스를 활용했을 때 보다 Full Table Scan이 훨씬 더 빨랐다
- 복합인덱스로 사용했을 때 Full Table Scan 보다 2배가량 빨랐다
그렇다면 복합인덱스로 사용하면 되겠네? -> 절대 아니다
데이터의 분포를 한 번 살펴보자

id는 두 개로 100만 건, 200만 건으로 분포된다
-> 인덱스를 탈 때 범위 탐색에 전혀 도움이 될 수 없음
1편에서 보았듯이 인덱스를 통한 탐색은 결국 인덱스로 범위를 탐색하고 데이터를 조회하려면 PK를 통한 페이지를 조회해야 한다.
인덱스로 Id를 1로 걸렀지만 100만 건의 데이터에 대해서 전부 페이지 조회를 다시 해야 하니까 Full Table Scan보다 느릴 수밖에 없는 것이다
- 인덱스가 식별 범위를 좁혀주지 못해 인덱스 테이블도 보고 인덱스 테이블에서 얻은 주소 테이블도 봐야 하니까 느림 (봐야 하는 탐색 범위라도 줄여 줬어야지_)
이에 대한 증거로 없는 memberId로 인덱스를 타게 되면 조회해야 할 범위가 없기 때문에 엄청난 속도로 반환된다

CreatedDate를 보자

이전에 생성했던 22-01-01 ~ 22-01-31까지의 데이터로 10만 건가량으로 데이터 분포가 이루어져 있다
그런데 우리가 조회했던 쿼리는 1900~2023-01-01까지의 데이터이다 따라서 인덱스를 통해 전혀 데이터 범위를 줄이지 못하고 있다
member 3에 대해서 1970 ~ 2023년까지 데이터를 100만 건 더 삽입하고 테스트를 해보자
-> 데이터 분포가 분산되어 저장시키는 경우

가장 빠른 결과를 볼 수 있다
- 같은 인덱스를 사용하더라도 데이터 분포에 따라 결과는 천차만별이다
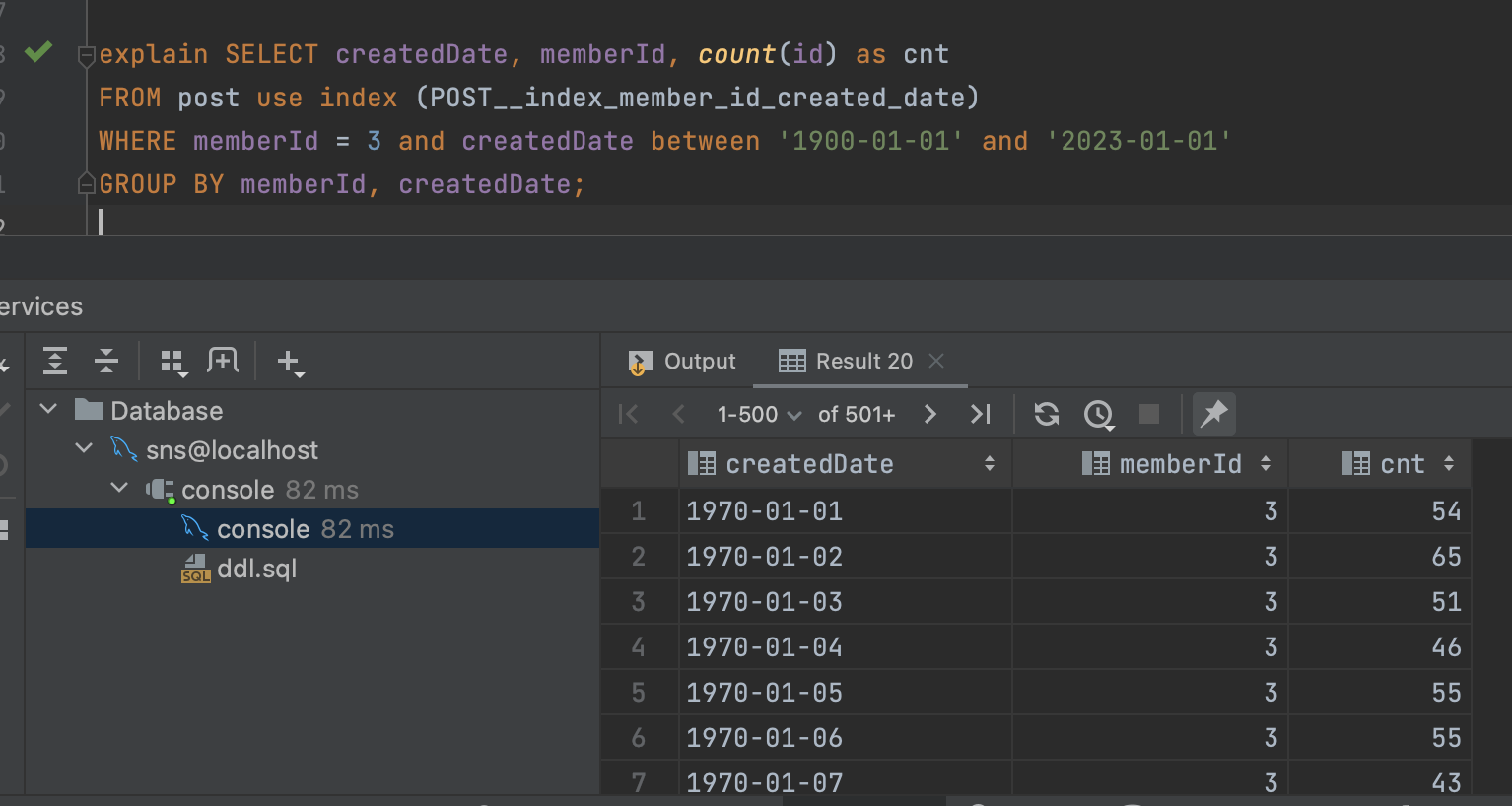
복합 인덱스를 보자
복합 인덱스를 사용했을 때가 속도가 가장 빨랐다. 이유는 memberId로 범위를 좁힌 후 memberId가 같을 경우 createdDate로 정렬되어 관리하기 때문
- memberId로 먼저 탐색범위를 줄인다 => 300만 건을 100만 건으로
- 남은 100만 건 데이터를 정렬된 createdDate로 탐색범위를 또 줄여서 탐색할 수 있게 해 줌
- group by에 두 인덱스가 포함되므로 group by에서도 index를 타게 해 줌
여러 가지 상황이 더 있을 수 있을 거 같은데 오늘은 이쯤 알아보도록 하자
결론
똑같은 인덱스를 타더라도 성능이 천차만별이 될 수 있다 항상 테스트를 해보며 우리의 서비스 방향과 어떤 데이터들이 쌓이게 될지를 고민하자 하지만 꼭 인덱스가 아니더라도 성능을 개선할 수 있다는 것도 꼭 알아두자
인덱스? 왜 인덱스여야 하는가?
- 데이터 분포도를 고려
- 어떤 컬럼들이 group by, order by에 같이 묶이는지
- 특정 인덱스에 따라서 결과가 변하는 것은 아니다
- 옵티마이저가 통계에 따라 인덱스를 선택하므로 여러 인덱스를 함부로 만들면 느린 인덱스를 타게 되는 경우도 있을 수 있으므로 explain을 통해 어떤 인덱스를 타는지 확인하고 비교해 볼 수 있어야 한다
- 현재 테스트에서는 강제했기 때문에 pass
인덱스 사용 시 주의 점
- 인덱스 필드를 가공하면 인덱스를 타지 않는다! (ex a*10, a(int)인데 string으로 사용할 때)
- 복합 인덱스
- 1번 인덱스와 2번 인덱스 일 때 2번 인덱스만 where에 들어오면 index를 타지 않음
- 1번 인덱스만 where문에 들어오면 1번 인덱스로 인덱스를 탈 수 있음
- -> 선두 인덱스를 잘 선택해야 함
- 하나의 쿼리에는 하나의 인덱스만 탄다
- index merge hint를 사용하면 가능하긴 하다
- where, order by, group by를 혼합해서 사용할 때에는 인덱스를 잘 고려
- where을 인덱스를 타서 잘 탐색했는데, order by에서 인덱스를 타지 못하면 전부 정렬해야 하는 상황이 옴
- 의도대로 인덱스가 동작하지 않을 수 있음 (explain 확인)
- 배포환경과 운영환경의 통계 데이터가 달라서 다르게 작동할 수 있음
- 인덱스로 인한 비용 고려 (쓰기)
- 컬럼의 카디널리티 고려!
참고:
https://joont92.github.io/db/mysql-index/
[db] mysql index
순차 IO / 랜덤 IO 기본적으로 하드는 데이터를 읽을때 원판 플래터를 회전시키며 데이터를 찾는다. 순차 IO란 시작위치에 간 뒤 쭉 읽어서 데이터를 찾는 것을 말하고, 랜덤 IO란 여러 위치를 탐색
joont92.github.io
'엑셈 경쟁력/DB 인사이드' 카테고리의 글 목록 (3 Page)
Data Artist Group, 엑셈 공식 블로그입니다.
blog.ex-em.com
더미데이터 삽입 참고:
https://github.com/j-easy/easy-random/wiki
Home
The simple, stupid random Java beans/records generator - j-easy/easy-random
github.com
'데이터베이스' 카테고리의 다른 글
| 데이터베이스 반정규화 (1) | 2023.09.06 |
|---|---|
| 데이터베이스 정규화 (0) | 2023.09.06 |
| 데이터베이스 커넥션 풀 (0) | 2023.09.05 |
| MySQL 인덱스 동작 확인하기 (0) | 2023.07.23 |
| 조회 성능 최적화를 위한 인덱스 (1) (0) | 2023.07.05 |



